Have you ever wanted to automate how you use a website? There are plenty of browser automation tools these days, but as a developer sometimes you just want to access the API!
For this tutorial I'll try to scrape flights from kayak.com.
In general please be nice with how you scrape.
The basics
Tip 1: Start with the mobile API
The first tip I'll share is that it's often much easier to reverse engineer the mobile API. This is because the mobile API is often simpler and more stable than the web API, typically in JSON format. For example, the web network requests will sometimes send back HTML which is a pain to parse. Luckily, Chrome offers an easy way to simulate a mobile device.
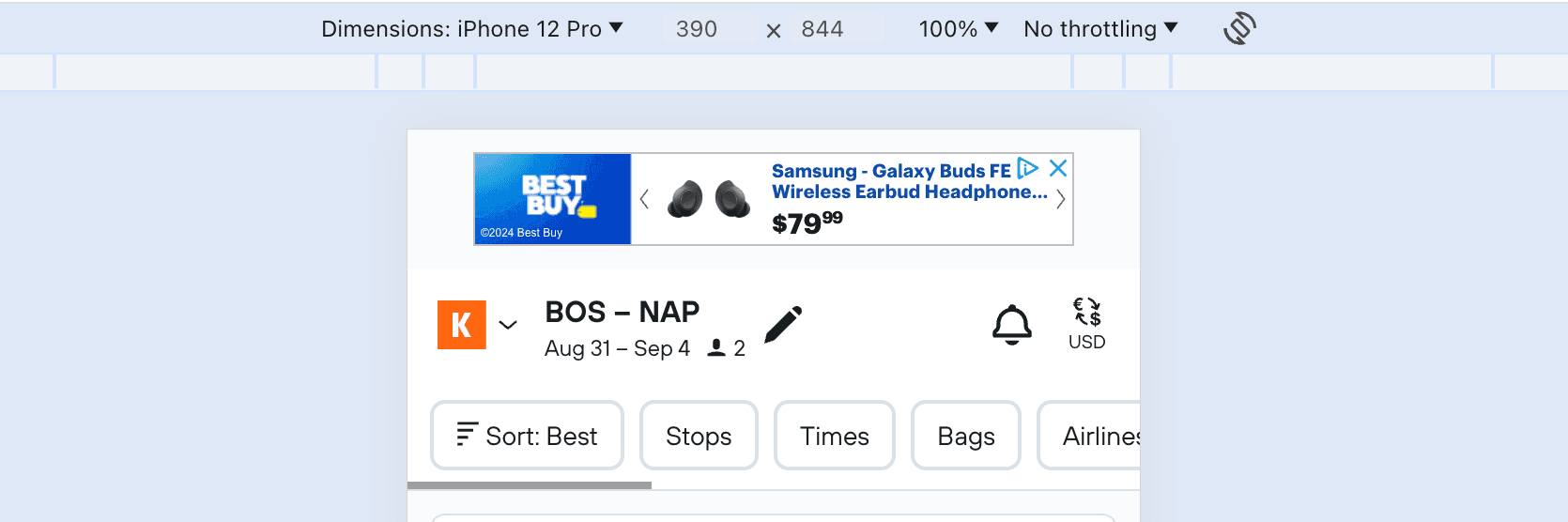
Now we can bust open the network tab of our developer tools and start looking at the requests. We're looking for something related to flight results.
It looks like there's a network call to https://www.kayak.com/i/api/search/v1/flights/poll which is what we want!

Tip 2: Use the right User-Agent
An important part to pay attention to is the User-Agent header. This is how the server knows we're a mobile device, but really it's just an arbitrary string.
The reason I point this out is some websites use the User-Agent to determine if you're a bot or not. It's best to copy exactly what you see in the browser request.
Testing it out
OK, let's try to make a request to the API and see what we get back. I'll use Ruby for this example:
conn = Faraday.new(
url: "https://www.kayak.com",
headers: {
"User-Agent" => "KayakiPhone/232.0.1 iOS/17.3.1 iPhone16,1",
"Accept-Language" => "en-US",
}
)
poll_response = conn.post("/i/api/search/v1/flights/poll") do |req|
req.headers["Content-Type"] = "application/json"
req.body = {
...
}.to_json
endand after running we get
"errors":[{"code":"ANONYMOUS_ACCESS_DENIED","description":"Anonymous access to KAYAK API denied"}]
Wait that's not right, what gives? 🤯
Tip 3: Get a valid session
Most websites require you to have a valid session to access their API. This is usually done by setting a cookie in your request. In my original screenshot of the poll request URL you can see it's actually part of the URL as an _sid_ parameter, and it's also set as a p1.med.sid cookie.
The easiest way around this is to simply make a request to the regular website first, save the cookies from that response, and then replay them in all future requests. For example, here is how to grab the cookies:
# Most languages have a "Cookie Jar" type
conn = Faraday.new(
url: "https://www.kayak.com",
headers: {
"User-Agent" => "KayakiPhone/232.0.1 iOS/17.3.1 iPhone16,1",
"Accept-Language" => "en-US",
}
)
# Note: I'm not hitting the API for this
response = @conn.get("/flights/BOS-NAP/2024-04-30/2024-05-07?a=kayak")
raise "Got invalid response: #{response.status}" unless response.status == 200
cookie_jar = HTTP::CookieJar.new
response.headers['set-cookie']&.split(', ').each do |cookie|
begin
HTTP::Cookie.parse(cookie, response.env.url).each do |parsed_cookie|
cookie_jar.add(parsed_cookie)
puts "Cookie: #{parsed_cookie.name}=#{parsed_cookie.value}"
end
rescue => e
puts "Skipped invalid cookie: #{e.message}"
next
end
endNow, let's feed this into our poll request:
poll_response = conn.post("/i/api/search/v1/flights/poll") do |req|
req.headers['Cookie'] = cookie_jar.cookies
.map { |cookie| "#{cookie.name}=#{cookie.value}" }
.join('; ')
req.headers["Content-Type"] = "application/json"
req.body = {
...
}.to_json
endThe rationale here is that most websites work for users that don't have an account, since only a small percentage of users will be logged in, so we just need to pretend we are one of those anonymous users.
Sadly, after running we get the same error. 😭
Copy everything
Tip 4: Copy the cURL command
There's another very handy feature of Chrome I held back on mentioning. You can right-click on a network request and copy it as a cURL command. This is a great way to exactly reproduce the request you see in the browser in your local terminal.
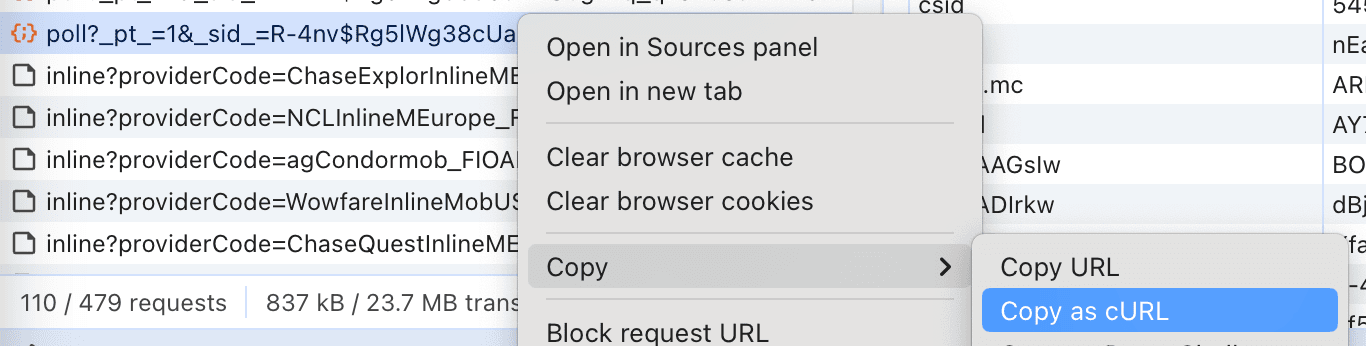
And running this in the terminal works exactly as expected! That means there is a slight difference between what we're sending in our code. Luckily, this is easily solved by process of elimination. After deleting a few headers from the copied cURL command, I'm able to get the same error once these headers are missing:
-H 'origin: https://www.kayak.com' \
-H 'referer: https://www.kayak.com/flights/BOS-NAP/2024-08-31/2024-09-04/2adults?sort=bestflight_a&a=kayak' \
It looks like KAYAK has another anti-bot detection that ensures API requests originate from the website. This is a common technique to prevent scraping. The solution is to simply add these headers to our request:
poll_response = @conn.post("/i/api/search/v1/flights/poll") do |req|
cookie_header = @cookie_jar.cookies
.map { |cookie| "#{cookie.name}=#{cookie.value}" }
.join('; ')
req.headers['Cookie'] = cookie_header
req.headers["Content-Type"] = "application/json"
req.body = {
...
}.to_json
req.headers['origin'] = "https://www.kayak.com"
req.headers['referer'] = "https://www.kayak.com/flights/BOS-NAP/2024-08-31/2024-09-04/2adults?sort=bestflight_a&a=kayak"
endAnd now we get the expected flight results! 🎉
You can view a full example of this code in my GitHub repository.
Bonus tip 5: Use a proxy app
If you're serious about reverse engineering, I highly recommend using an app like Charles Proxy to help with inspecting network requests. This allows you to see all network requests from your computer, not only the ones in the browser. There is also an iOS app which allows you to inspect network requests from your phone.
A free alternative that's also great is mitmproxy.